Quick Answer
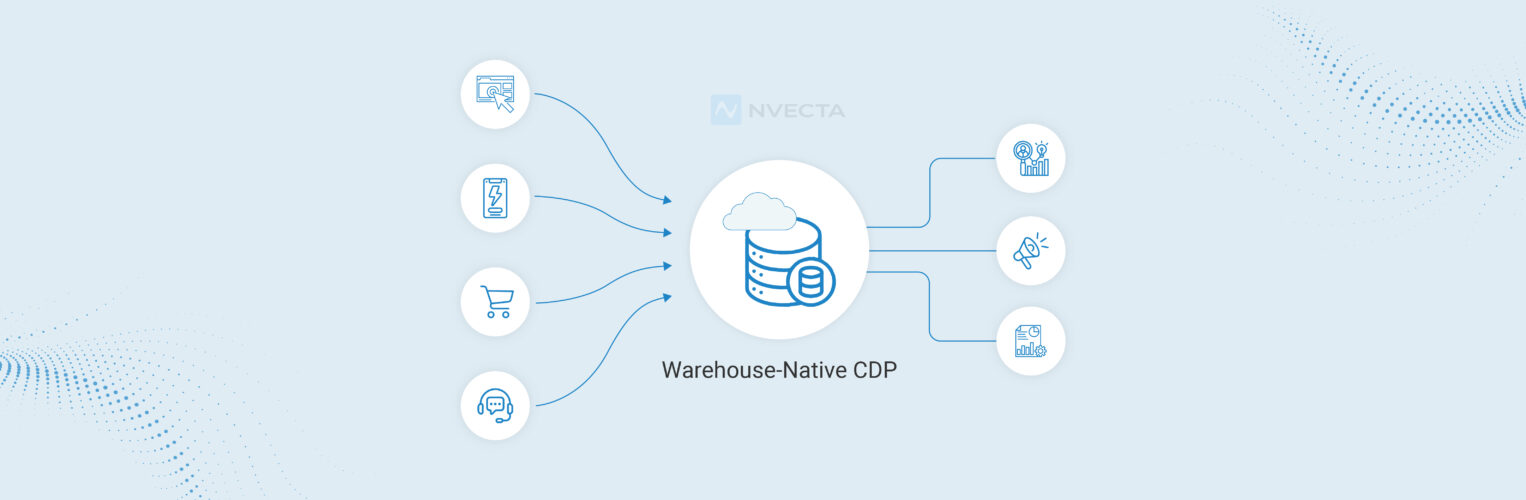
A warehouse-native CDP is a customer data platform that operates directly on your existing cloud data warehouse — such as Snowflake, BigQuery, Redshift, or Databricks — without copying customer data into a separate vendor system. Identity resolution, segmentation, and audience activation all run in-place inside the warehouse, giving teams complete data ownership with zero duplication.
Customer data has become one of the most valuable assets for modern businesses. Every interaction a user has with a brand generates information. Website visits, app usage, purchases, email engagement, product behaviour, and support conversations all produce signals that can help teams understand their customers better.
For years, companies relied on traditional Customer Data Platforms to bring this information together. At the time, it made sense. Data lived in different systems, and marketing teams needed a way to unify profiles and launch campaigns. But the way data is stored, managed and analysed has changed dramatically.
Cloud data warehouses are now the foundation of analytics. They hold massive volumes of structured and unstructured data and power reporting, machine learning and business intelligence. As warehouses became the centre of the data ecosystem, traditional CDPs started to feel disconnected, slow and expensive.
This shift has given rise to warehouse native CDPs. Instead of pulling data out of the warehouse, these platforms work directly inside it. For many modern brands, this approach aligns far better with how their teams already operate, an evolution that platforms like Nvecta are designed to complement by turning warehouse-driven insights into real-time customer engagement.
What Is a Warehouse Native CDP
A warehouse native CDP is a Customer Data Platform that runs directly on top of a company’s cloud data warehouse. Rather than copying customer data into a separate proprietary database, the data stays exactly where it is.
The warehouse becomes the single trusted source for all customer information. The CDP layer simply adds tools and logic that make the data usable for marketing, product and growth teams.
These capabilities usually include identity resolution, profile unification, segmentation and audience activation.
Because the data never leaves the warehouse, teams can work with complete datasets, including raw events, historical records and enriched attributes. This architecture also supports data warehouse migration solutions, helping organizations move legacy systems to modern cloud platforms without disrupting data accessibility and governance.
This is especially common for companies using platforms like Snowflake and Google BigQuery, which are already designed for scale, performance and governance.
A warehouse native CDP does not try to replace the warehouse. Instead, it builds on top of it and fits naturally into the modern data stack.
What Are Traditional CDPs

Traditional Customer Data Platforms were created to solve a different problem. A decade ago, customer data was scattered across many disconnected systems.
Marketing teams had limited access to raw data and depended heavily on engineering teams for support.
Traditional CDPs positioned themselves as centralised hubs. They collected data from websites, mobile apps, CRM tools, ad platforms and email systems. Once ingested, the data was stored inside the CDP vendor’s own environment.
From there, customer profiles were created, and marketers used built-in user interfaces to build segments, personalise experiences and activate audiences across channels like email, paid media and analytics platforms.
For many organizations this was a major step forward. It reduced fragmentation and allowed marketers to work more independently.
However, the model also introduced new trade-offs that became more obvious as data volumes and complexity increased.
Why Traditional CDPs Are Falling Short Today
Most traditional CDPs were built before cloud data warehouses became the core of analytics and decision-making. As a result, they struggle to keep up with modern requirements.
One of the biggest issues is data duplication. In most setups, customer data already lives in the warehouse.
Traditional CDPs require that same data to be copied again into their own system. This creates multiple versions of the truth and increases the risk of inconsistencies.
Cost is another major concern. Companies pay for warehouse storage and compute, and then pay again for CDP storage processing and licensing. As data grows, these costs scale quickly.
Sync latency is also a common problem. When data changes in one system, it may not update immediately in the other. This can lead to outdated segments, delayed campaigns and inaccurate reporting.
There is also the issue of flexibility. Traditional CDPs often rely on predefined schemas and user interfaces.
While this works for basic use cases, it becomes limiting when teams want to build custom logic, advanced models or complex behavioural analysis.
Because of these challenges, many data-driven organisations are reassessing whether traditional CDPs still make sense.
How a Warehouse Native CDP Works
Warehouse native CDPs take a much simpler and more modern approach. Instead of moving data around, they bring CDP functionality directly to the warehouse.
The typical flow starts with data ingestion. Customer data from various sources is loaded into the warehouse using ELT pipelines. This data may include events, transactions, CRM records, product usage and third-party enrichments.
Next identity resolution logic is applied. Using SQL or transformation tools, teams link identifiers such as email, device ID, user ID and cookies to create unified customer profiles.
Once profiles are available, marketers and analysts can build segments directly on warehouse tables. Because this happens inside the warehouse, they can use the full power of SQL and analytics tools.
Finally, audiences are activated from the warehouse into downstream tools. This may include email platforms, ad networks, personalisation engines or customer engagement software.
Since everything happens in one place, there is no need for constant syncing or reconciliation. Teams always work with the most up-to-date data.
Benefits of a Warehouse Native CDP
1. A True Single Source of Truth
All customer data lives in one governed environment. CRM records transactions, behavioural events, and product data, which are stored together and managed consistently. This eliminates confusion and improves trust across teams.
2. Deeper Analytics and Better Personalisation
Because teams work directly with raw data, they are not limited by predefined views. They can analyze long term behavior, build custom metrics and combine marketing, product and revenue data in powerful ways. This enables more accurate personalisation and better decision-making.
3. Lower Costs at Scale
Warehouse native CDPs avoid duplicate storage and make use of existing warehouse compute. This significantly reduces the total cost of ownership, especially as data volumes grow.
4. Stronger Governance and Compliance
Data privacy, access control and lineage tracking stay centralised in the warehouse. This makes it easier to comply with regulations like GDPR and CCPA and reduces operational risk.
5. Better Collaboration Between Teams
When everyone works on the same data foundation, marketing, analytics, product and engineering teams can collaborate more effectively. There is less friction and fewer handoffs.
Why Modern Brands Are Moving Away From Traditional CDPs
Modern brands operate in fast-moving environments. They need to experiment, quickly adapt to customer behaviour, and deliver consistent experiences across channels.
This requires flexible data models, real-time insights and close alignment between teams. Traditional CDPs often add another layer of abstraction that slows things down.
As organizations modernize their data infrastructure, many are also spending more time comparing-traditional-cdp-and-composable-cdp comparing traditional CDP and composable CDP approaches to evaluate which model offers better flexibility, governance, and scalability for long-term customer data management.
This comparison has become especially important for teams building around cloud warehouses like Snowflake and BigQuery.
Warehouse native CDPs fit naturally into the modern data stack. They support composable architectures where each tool does one job well. Instead of creating another silo, they extend the value of the existing data infrastructure.
As a result, more companies are choosing to build CDP capabilities on top of their warehouse rather than relying on standalone systems.
Warehouse Native CDP vs Traditional CDP vs Composable CDP
Not all customer data platforms are built the same way. As the market matures, three distinct approaches have emerged — and each one serves a different kind of team. If you are deciding which path fits your organisation, this comparison cuts through the noise.
| Factor | Warehouse Native CDP | Traditional (SaaS) CDP | Composable CDP |
|---|---|---|---|
| Where data lives | Your warehouse (Snowflake, BigQuery, Redshift, Databricks) | Vendor-managed proprietary database | Your warehouse + modular best-of-breed tools |
| Data duplication | None — zero-copy architecture | Yes — full copy into vendor system | Minimal within warehouse; copies occur at activation |
| Real-time capability | Batch-optimised; real-time needs extra streaming layers | Built-in real-time out of the box | Batch-optimised; real-time requires additional tooling |
| Engineering effort | Moderate — familiar SQL workflows | Low — UI-driven, minimal engineering | High — assembling and maintaining multiple tools |
| Vendor lock-in | Low — data stays in your infrastructure | High — data stored inside vendor platform | Low — modular by design |
| Cost profile | Uses existing warehouse compute — lower TCO at scale | Higher licensing + duplicate storage fees | Can exceed standalone CDP if many tools are required |
| Best fit for | Data-mature teams with existing warehouse investment | Marketing-led orgs needing fast time-to-value | Engineering-heavy teams wanting maximum flexibility |
The honest answer is that there is no universal winner here. Teams with a mature Snowflake or BigQuery environment and strong data engineering will usually get the most value from a warehouse-native or composable approach. Teams that need campaigns running in days, not weeks, tend to lean on traditional CDPs for their out-of-the-box speed. The hybrid model — where the warehouse handles analytics and a platform like NVECTA handles real-time activation — is increasingly how modern organisations get the best of both.
Zero-Copy Architecture and What It Means for Your CDP
One phrase you will hear more frequently in 2026 CDP conversations is zero-copy architecture. It is not just marketing language — it describes a meaningful shift in how customer data is managed.
In the traditional model, data moved through a chain of copies. It was extracted from source systems, loaded into the CDP vendor’s database, then copied again into activation tools like email platforms, ad networks and CRM systems. Every copy created new governance risk, new storage costs and a new surface area for data breaches.
Zero-copy flips this logic entirely. Instead of moving data to the tools, the tools come to the data. Customer profiles, segments and attributes are computed directly inside Snowflake, BigQuery, Redshift or Databricks. Activation happens through reverse ETL or native warehouse connectors — the raw data itself never leaves the governed environment.
The practical benefits are significant. Data governance policies set inside the warehouse automatically apply to everything built on top of it. GDPR deletion requests, access controls and audit trails are all handled in one place rather than chased across five vendor systems. Storage costs drop because there is only one copy of each record. And because the activation layer always reads from the latest warehouse state, there are no sync delays or stale segments.
In Gartner’s 2026 Magic Quadrant for CDPs, zero-copy querying was highlighted as a key architectural differentiator, with vendors like Hightouch and Uniphore specifically recognised for advancing this model. The terminology has moved from niche data engineering concept to mainstream evaluation criterion in under two years.
It is worth noting that zero-copy does not mean zero data movement at the point of activation. When a segment is pushed to an email platform or an ad network, those downstream tools still receive customer identifiers. What zero-copy eliminates is the redundant duplication of the full dataset inside yet another vendor’s proprietary storage layer.
Does a Warehouse Native CDP Support Real-Time Activation?
This is the most common question from teams evaluating warehouse-native CDPs — and it deserves a straight answer rather than a vague “it depends”.
The honest answer is: warehouse-native CDPs are excellent at batch and near-real-time use cases, but they face genuine constraints when milliseconds matter.
Cloud data warehouses like Snowflake and BigQuery are built for analytical workloads — scanning large datasets, running complex SQL queries and producing aggregated reports. They are not optimised for the sub-second profile lookups that power in-session personalisation, cart abandonment triggers firing mid-browse, or fraud detection that needs to stop a transaction before it completes.
Achieving true millisecond latency on warehouse infrastructure typically requires adding caching layers, streaming ingestion pipelines and a separate profile-serving API — which is, in effect, rebuilding the operational data layer that a purpose-built CDP already provides natively.
That said, the vast majority of marketing use cases do not actually require millisecond response times. Weekly audience syncs for paid media campaigns, daily segment refreshes, churn model scoring, lifecycle email triggers and personalisation based on recent behaviour all work extremely well with a warehouse-native approach.
Where the architecture genuinely shines is in the depth of the data it can bring to those activations. Because segments are built directly on warehouse tables, they can incorporate full transactional history, product usage data, revenue metrics and any custom attribute the data team has modelled — without any of the schema restrictions that traditional CDPs impose.
The emerging answer to the real-time gap is a hybrid model. The warehouse handles analytics, model training and batch audience building, while a real-time layer — like the one NVECTA provides through its Composable CDP — handles time-sensitive activations. Warehouse-built profiles feed the engagement layer, which can then trigger email, push, SMS, WhatsApp and on-site messages with the freshness and context the warehouse provides, at the speed the customer moment demands.
Want a broader view of how CDPs work before going deeper on warehouse-native architecture? Read our complete guide: What Is a Customer Data Platform (CDP)? A Comprehensive Guide — it covers CDP types, use cases, and how to choose the right approach for your team.
How NVECTA Complements a Warehouse Native CDP Strategy with Its Composable CDP
Many brands today are choosing to build their customer data strategy around their cloud data warehouse.
Rather than transferring data into multiple external systems, they prefer to keep it centralised, secure, and fully governed in one place.
NVECTA enables this model through its warehouse native architecture, referred to as its Composable CDP.
Customer data stays within the warehouse as the single source of truth, without being copied into separate proprietary systems. Identity resolution, profile creation, and segmentation are built directly on warehouse data models.
This gives teams access to their customer data, including transactions, product activity, CRM information, and behavioural signals, without being restricted.
NVECTA also enables direct audience activation from warehouse-built segments.
After profiles and audiences are created, brands can reach users across email, push notifications, SMS, WhatsApp, and on-site messaging from the same framework.
Campaigns can be triggered using real-time behaviour, attributes, or lifecycle stages.
The result is a more efficient and simplified setup. Data teams retain full governance and control within the warehouse, while marketing teams can launch and optimise campaigns independently without relying heavily on engineering support.
With its Composable CDP, NVECTA brings together warehouse native data management and cross-channel engagement in a single framework, helping modern brands move from insight to action more efficiently.
Final Thoughts
The rise of warehouse native CDPs proves a broader shift in how modern brands think about customer data. Ownership flexibility and scalability are becoming more important than ever.
By building CDP capabilities directly on platforms like Snowflake and BigQuery, organisations gain deeper insights, stronger governance and better cost efficiency. They also create a foundation that can evolve along with their business.
When combined with a customer engagement platform like NVECTA, this approach allows companies to move seamlessly from data to action. Insights are not just stored or analysed. They are used to create timely, relevant and personalised customer experiences.
For brands looking to future-proof their data strategy, the move toward warehouse native CDPs is not just a trend. It is a logical next step.
Frequently Asked Questions
What is a warehouse-native CDP?
A warehouse-native CDP is a customer data platform that runs directly on your existing cloud data warehouse — Snowflake, BigQuery, Redshift or Databricks — without copying data into a separate vendor system. Identity resolution, audience segmentation and activation all happen inside the warehouse, giving your team full data ownership and eliminating unnecessary duplication.
How is a warehouse-native CDP different from a composable CDP?
The terms overlap significantly but are not identical. Most composable CDPs are warehouse-native, meaning they use your warehouse as the foundation and layer modular tools on top for identity resolution, segmentation and activation. A warehouse-native CDP is the architecture; composable CDP describes the modular assembly pattern used to build out the full capability stack. You can have a warehouse-native setup without a fully composable approach.
Does a warehouse-native CDP work with Snowflake and BigQuery?
Yes. Warehouse-native CDPs are specifically designed to run on top of cloud data warehouses like Snowflake, Google BigQuery, Amazon Redshift and Databricks. The CDP layer connects directly to your existing warehouse schema, builds customer profiles and segments using SQL and transformation logic, and activates audiences from there into downstream marketing and analytics tools.
What are the limitations of a warehouse-native CDP?
The main limitation is real-time activation. Warehouses are optimised for analytical workloads, not sub-second profile lookups. Use cases that require millisecond response times — like in-session personalisation or real-time fraud detection — need additional streaming infrastructure. Warehouse-native CDPs also require a reasonably mature data engineering function to set up and maintain identity resolution, transformation pipelines and activation connectors.
When should I choose a traditional CDP instead of a warehouse-native one?
A traditional SaaS CDP makes more sense when your marketing team needs fast time-to-value with minimal engineering involvement, when real-time campaign triggers are central to your strategy, or when you do not yet have a mature cloud data warehouse. If speed of execution matters more than architectural control, a traditional CDP’s packaged UI, prebuilt integrations and managed infrastructure will get you there faster. Many organisations also combine both — using the warehouse for analytics and a platform like NVECTA for real-time engagement on top of warehouse-built profiles.